Nota do autor: Este texto foi originalmente escrito para um projeto de 73 páginas (inclui figuras e código-fonte) que fiz na faculdade intitulado BANCO DE DADOS ORIENTADO A DOCUMENTOS – UMA APLICAÇÂO PRÁTICA e seguiu alguns requerimentos burocráticos que eu apaguei e outros que mantive. O projeto completo inclui uma aplicação em Delphi para Windows e outra para Arduino/ESP8266 e será tudo detalhado em outros posts.
Quando pensamos hoje em banco de dados quase sempre ainda estamos pensando em um banco de dados relacional. Segundo pesquisa mensal da consultoria austríaca Solid IT, os
quatro SGBD (Sistema Gerenciador de Banco de Dados) mais populares são relacionais, o que corresponde a 75% do total.

O que pode surpreender muitos programadores que por não conhecerem as alternativas podem se espantar por esse número não ser 100%. Mas provavelmente todo programador deve ter se deparado com alguma situação em que seu SGBD (relacional) favorito gerava um incômodo que precisou ser contornado de alguma forma pouco ou nada elegante e que poderia ter sido resolvido com a troca do paradigma.
Mas antes de introduzir a alternativa é conveniente dar um exemplo do tipo de problema que ela resolve.
Considere um problema comum de IoT (Internet of Things – Internet das Coisas) onde você tem um sensor para acompanhar o desenvolvimento minuto a minuto de uma certa grandeza (temperatura, por exemplo) e deseja armazenar isso em um banco de dados para análise posterior. A informação mínima útil a armazenar seria a temperatura e o horário da medição. Uma representação tabular da informação armazenada ficaria assim:
| Ordem |
Temperatura |
Horário |
| 1 |
22,12 |
01/05/2020 15:10 |
| 2 |
23,45 |
01/05/2020 15:11 |
| 3 |
25,10 |
01/05/2020 15:12 |
| 4 |
26,13 |
01/05/2020 15:13 |
Mas digamos que em um momento qualquer no futuro você decidiu acrescentar mais um sensor. Em uma aplicação convencional usando um SGBD relacional, além de ter que atualizar todos os componentes do projeto que acessam o banco de dados é preciso alterar o próprio banco de dados mudando o seu schema (sua estrutura lógica) acrescentando no mínimo uma coluna (campo), e o resultado poderia ser algo assim:
| Ordem |
Temperatura |
Horário |
Temperatura2 |
| 1 |
22,12 |
01/05/2020 15:10 |
|
| 2 |
23,45 |
01/05/2020 15:11 |
|
| 3 |
25,10 |
01/05/2020 15:12 |
|
| 4 |
26,13 |
01/05/2020 15:13 |
|
| … |
… |
… |
… |
| 199 |
25,12 |
20/05/2020 11:00 |
28,10 |
| 200 |
26,13 |
20/05/2020 11:01 |
29,05 |
| 201 |
27,08 |
20/05/2020 11:02 |
30,12 |
| 202 |
29,10 |
20/05/2020 11:03 |
31,10 |
O fato de todos os registros anteriores à alteração ficarem vazios pode ou não ser um problema, mas o fato de ter que alterar o schema é. Além do mero incômodo de ser um passo adicional, normalmente alterar o schema requer downtime. Todos os acessos à tabela a modificar precisam ser interrompidos durante a operação. Em um sistema local isso pode significar apenas “pedir a todo mundo que saia do sistema”, mas à medida que aumenta a complexidade e a utilização do sistema, interromper o acesso aos dados mesmo que por um intervalo curto de tempo vai se tornando uma decisão mais difícil, impactando negativamente na escalabilidade. Sam Saffron, um dos criadores do popular software de código aberto de gerenciamento de listas de discussão Discourse, afirma que “uma das razões mais comuns para interrupções de serviço durante o deployment de uma aplicação é a alteração do schema do banco de dados”.
Agora digamos que você como desenvolvedor antecipa a necessidade futura de acrescentar sensores e pensando em evitar esse passo adicional e o downtime, decide criar a tabela já com os campos necessários para acomodar mais sensores. Mas quantos campos adicionais antecipar? Dois? Cinco? Dez? Cem? E se você precisar fazer alguma alteração que torne essa antecipação inútil? O nosso exemplo é propositalmente bem simples, mas existem outras situações similares bem mais complexas.
Nesse ponto é interessante avaliar os SGBD NoSQL.
Bancos de dados NoSQL
NoSQL é um paradigma de banco de dados que é modelado de uma forma diferente da tradicional representação tabular dos bancos relacionais. Esse tipo de banco de dados existe desde os anos 1960, mas apenas cerca de dez anos atrás foi o adotado o termo “NoSQL” para se referir ao paradigma. Bancos NoSQL tem um foco em simplicidade de projeto e escalabilidade e suas estruturas de dados são diferentes das usadas em bancos relacionais fazendo com que algumas operações sejam mais rápidas em NoSQL.
Os requerimentos do nosso exemplo são a capacidade de mudar o schema facilmente e fazer buscas simples no banco de dados. O primeiro é uma característica dos bancos NoSQL mas os recursos de busca dependem do SGBD NoSQL escolhido.
Os SGBD NoSQL podem ser divididos em quatro grandes categorias:
- Chave-Valor (key-value);
- Armazenamento de Documentos (document-store);
- Armazenamento de coluna ampla (wide colum stores);
- Graph Database.
Novamente usando como referência a DB-Engines, podemos ver que os modelos mais populares são chave-valor e armazenamento de documentos:
Por brevidade, vamos nos ater a analisar apenas esses dois modelos.
Chave-Valor
Nesse modelo o banco de dados usa um simples método chave-valor para armazenar os dados. É mais fácil entender esse método pensando que um dicionário é um exemplo de chave-valor: a chave sendo uma palavra e o valor sendo o significado. O nome do método pode ser enganador, levando você a pensar que o “valor” pode ser uma entidade apenas, mas não é bem assim. Abaixo temos um exemplo perfeitamente válido de armazenamento chave-valor:
| Chave |
Valor |
| 1 |
22.5,10/04/2020 12:35 |
| 2 |
23.6,10/04/2020 12:36 |
| 3 |
24.2,10/04/2020 12:37 |
| 4 |
25.1,10/04/2020 12:38 |
No exemplo acima, cada chave dá acesso a duas entidades: uma temperatura e o horário. Chave-valor não tem nenhum schema definido e você está livre para mais tarde ao descobrir que precisa colocar mais um sensor fazer algo assim:
| Chave |
Valor |
| 1 |
22.5, 10/04/2020 12:35 |
| 2 |
23.6, 10/04/2020 12:36 |
| 3 |
24.2, 10/04/2020 12:37 |
| 4 |
25.1, 10/04/2020 12:38 |
| … |
… |
| 199 |
27.2, 20/05/2020 17:23, 28.9 |
| 200 |
28.4, 20/05/2020 17:24, 27.9 |
| 201 |
27.3, 20/05/2020 17:25, 26.5 |
| 202 |
26.2, 20/05/2020 17:26, 25.3 |
Como se pode ver, o valor do segundo sensor foi simplesmente acrescentado aos novos registros armazenados. Isso pode ser feito indefinidamente e não apenas com o valor de outros sensores. Você pode adicionar qualquer outra informação ao registro que queira, como notas. Você faz o seu schema e isso é transparente para o banco de dados.
Além disso, como a única coisa que define a chave é que é um valor que só pode ocorrer uma vez no banco de dados, você pode perfeitamente usar o horário como chave:
| Chave |
Valor |
| 10/04/2020 12:35 |
22.5 |
| 10/04/2020 12:36 |
23.6 |
| 10/04/2020 12:37 |
24.2 |
| 10/04/2020 12:38 |
25.1 |
| … |
… |
| 20/05/2020 17:23 |
27.2, 28.9 |
| 20/05/2020 17:24 |
28.4, 27.9 |
| 20/05/2020 17:25 |
27.3, 26.5 |
| 20/05/2020 17:26 |
26.2, 25.3 |
Parece perfeito para a nossa aplicação, mas existe um problema. Segundo a IBM Cloud Education:
“Em geral, armazenamentos key-value não tem linguagem de consulta. Eles simplesmente proporcionam um modo de armazenar, recuperar e atualizar dados usando simples comandos GET, PUT e DELETE. A simplicidade deste modelo torna um armazenamento key-value rápido, fácil de usar, escalável, portável e flexível.”
Então com satisfazer o requerimento de poder fazer buscas no banco? De acordo com DB-Engines, o mais popular SGBD com suporte a chave-valor é o Redis:

Este parece suportar buscas, mas após uma verificação superficial da documentação não conseguimos uma resposta clara de como fazer o tipo de busca que desejamos.
Armazenamento de Documentos
Esse nome pode dar a impressão inicial que essa categoria objetiva armazenar arquivos do Word, Excel, AutoCAD, etc. Os arquivos que nós geralmente chamaríamos de “documentos” em um computador. Mas não se trata disso. No contexto dos bancos de dados um documento pode ser algo tão simples quanto a seguinte linha de texto:
{“Temperatura1”:”22.4”}
De acordo com DB-Engines, o mais popular SGBD orientado a documentos é o MongoDB:
Em teoria você pode armazenar o documento em qualquer formato que queira, mas se você quer aproveitar as vantagens do NoSQL é prudente seguir formatos padronizados e cada SGBD tem suas preferências, sendo os mais comuns XML e JSON. Abaixo uma comparação simples dos dois formatos:
| XML |
JSON |
| <temperatura1>22.4</temperatura1>
<horário>10/12/2019 10:23</horário> |
{“temperatura1”:”22.4”;
“horário”:” 10/12/2019 10:23”} |
Como se pode notar o formato JSON é mais “natural”, mais fácil de ler e menos “verboso”, isto é: requer menos texto para transmitir a mesma informação. E de fato o mais popular SGBD NoSQL, o MongoDB, optou pelo JSON. E acabamos optando por esse também.
Os documentos não seguem nenhum schema rígido, por isso você pode a qualquer tempo adicionar novos campos ao documento, como no exemplo abaixo:
| JSON |
| {“temperatura1”:”22.4”;
“horário”:” 10/12/2019 10:23”} |
| {“temperatura1”:”23.7”;
“horário”:” 10/12/2019 10:24”} |
| {“temperatura1”:”23.7”;
“temperatura2”:”24.2”;
“horário”:” 10/12/2019 10:25”} |
| {“temperatura1”:”23.7”;
“temperatura2”:”24.8”;
“horário”:” 10/12/2019 10:25”} |
No exemplo nós simplesmente acrescentamos um campo a mais: temperatura2, mas novos campos podem ser acrescentados indefinidamente. Quanto ao nosso requerimento de fazer buscas nos dados, a documentação do MongoDB nesse aspecto é muito mais fácil de entender que a do Redis.
É importante notar que, mesmo usando JSON, document-store desperdiça muito espaço em comparação com um banco de dados relacional ou mesmo o modelo chave-valor por causa da alta repetição de informação. Por exemplo, digamos que desejamos apenas armazenar o valor em ponto flutuante de dois sensores no formato: “12,34” e que esse valor seja armazenado como string ASCII (cinco bytes por valor armazenado). Vamos considerar um “id” para identificar o registro, também string, com dois bytes:
Banco Relacional:
| Id |
Sensor1 |
Sensor2 |
| 01 |
23,34 |
23,45 |
Cada registro ocupa 12 bytes
Agora, o mesmo registro codificado como JSON:
{
“Id”=”01”
“Sensor1”:”23,34”;
“Sensor2”:”23,45”;
}
Como cada caractere precisa ser contado, a mesma quantidade de informação ocupa agora (ignorando caracteres de quebra de linha) 47 bytes por registro. Essa diferença só piora à medida que mais valores precisarem ser armazenados em cada documento. Em muitas aplicações essa diferença é irrelevante diante das vantagens, mas precisa ser levada em consideração onde espaço é problemático, como nas aplicações embarcadas. Espaço não será problema na nossa demonstração, pois mesmo na versão gratuita, com 500MB de espaço, o serviço escolhido pode suportar nossos requerimentos básicos por mais de três anos.
Podemos reduzir essa desvantagem no uso de espaço usando um formato binário de codificação como o BSON, mas em alguns casos BSON pode ocupar ainda mais espaço que JSON porque, de acordo com o FAQ “…adiciona informação extra aos documentos, como o comprimento das strings e subobjetos” e tem a desvantagem de não ser uma codificação legível por humanos.
Suporte a relações
Apesar de NoSQL se referir especificamente a bancos de dados não relacionais achar que você não pode armazenar relações em um bancos de dados NoSQL é um engano. Segundo a MONGODB, Inc: “Um equívoco comum é achar que bancos de dados NoSQL ou bancos de dados não-relacionais não armazenam dados de relacionamento bem. Bancos de dados NoSQL podem armazenar dados de relacionamento – eles apenas o fazem diferentemente de como é feito pelos bancos de dados relacionais. ”
Então não existe problema se futuramente nosso projeto necessitar de suporte a relações.
Diante do exposto, decidi pelo uso do modelo Armazenamento de Documentos com o MongoDB como SGBD.
Para demonstrar o uso de NoSQL irei usar um Arduino com dois sensores de temperatura publicando uma vez por minutos as temperaturas em um servidor NoSQL MongoDB Atlas e uma interface de usuário Windows onde se pode coletar e analisar esses dados. O projeto inteiro foi desenvolvido em três linguagens: javascript nos scripts Atlas, Delphi na aplicação Windows que fornece a interface gráfica com usuário e C++ no programa que roda no Arduino.
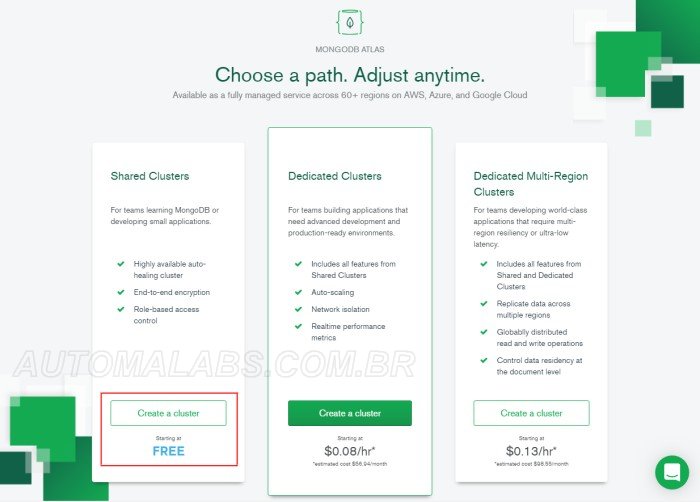
Nesta aplicação foi descartado o uso de um servidor de banco de dados NoSQL local porque reduziria sua utilidade. Dentre as opções online optamos pelo MongoDB por oferecer um serviço gratuito na forma do MongoDB Atlas. A única limitação dessa versão gratuita que afeta nossa demonstração é estar limitada a 500MB.
Próxima parte: Criando e configurando uma conta MongoDB Atlas
















Comentários